RAO: Nowa Era Optymalizacji Zastępująca SEO

Wstęp
Retrieval‑Augmented Optimization (RAO) to nowy sposób myślenia o widoczności w sieci — prosty, skuteczny i dostosowany do wyszukiwarek opartych na sztucznej inteligencji. Teza: RAO może zastąpić klasyczne SEO, bo lepiej rozumie kontekst i potrzeby użytkownika niż tradycyjne techniki optymalizacji.
W najprostszych słowach RAO polega na tym, że systemy AI łączą inteligentne wyszukiwanie dokumentów (retrieval) z generowaniem i oceną treści, aby dostarczyć użytkownikowi najbardziej relewantną odpowiedź. W przeciwieństwie do klasycznego SEO, które skupia się na słowach kluczowych, linkach i strukturze strony, RAO ocenia wartość informacji w czasie rzeczywistym i preferuje treści najlepiej odpowiadające zapytaniu.
Problem polega na tym, że algorytmy i AI różnią się sposobem działania: algorytmy wykonują zaprogramowane reguły, podczas gdy AI uczy się i adaptuje — co daje przewagę RAO, ale wymaga stałego nadzoru i jakości danych. Dodatkowo automatyzacja w social media i marketingu pokazuje, jak AI może skalować personalizację i raportowanie, lecz potrzebuje ludzkiego nadzoru, by uniknąć błędów i uprzedzeń.
W dalszych częściach artykułu przedstawię praktyczne wskazówki i przykłady wdrożeń RAO (od audytu treści po automatyzację publikacji) oraz pokażę, jak Lumi Zone pomaga firmom przejść na RAO krok po kroku. Przeczytaj dalej, by zobaczyć praktyczny plan działania — dalsze sekcje odwołują się do materiałów wskazanych przez autora.

3. Jak działa RAO — mechanika Retrieval‑Augmented Optimization i co to oznacza dla Twojej strony
Retrieval‑Augmented Optimization (RAO) to podejście, które łączy klasyczne wyszukiwanie informacji z generatywnymi modelami językowymi. W praktyce oznacza to: zamiast liczyć wyłącznie na statyczne sygnały SEO (słowa kluczowe, linki), system najpierw wyszukuje relewantne fragmenty treści, a potem generuje skondensowaną, dopasowaną odpowiedź. To połączenie retrievera + readera zmienia sposób, w jaki oceniana i serwowana jest treść.
Techniczne elementy RAO — wyjaśnione prosto
- Retriever — moduł, który szybko znajduje dokumenty lub fragmenty pasujące do zapytania. Myśl o nim jak o inteligentnym filtrze: nie zwraca całej bazy, tylko najbardziej obiecujące kawałki.
- Index (indeks wektorowy) — sposób przechowywania treści w formie wektorów, umożliwiający szybkie porównania. Zamiast przeszukiwać każdy dokument słowo po słowie, porównujemy wektory.
- Embeddings — reprezentacje tekstu jako wektorów liczbowych, które „łapią” znaczenie zdań i dokumentów. To dzięki embeddings retriever rozumie, że „kupno auta” i „zakup samochodu” to bliskoznaczne intencje.
- Reranker — warstwa porządkująca. Po wstępnym przefiltrowaniu retriever może zwrócić setki fragmentów; reranker ocenia je dokładniej i ustawia w kolejności najlepszych.
- Generative reader — model językowy, który łączy pobrane fragmenty i generuje spójną odpowiedź. To on formułuje tekst, podsumowuje lub porównuje informacje, często dołączając odwołania do źródeł.
- Wektorowe bazy danych — specjalne silniki (np. Pinecone, Milvus, czy open-source rozwiązania), które przechowują embeddings i umożliwiają bardzo szybkie wyszukiwanie semantyczne.
Rola jakości źródeł, aktualności i promptowania
RAO mocno zależy od jakości i świeżości indeksowanych treści. Jeżeli baza zawiera przestarzałe lub błędne materiały, generowana odpowiedź będzie równie zawodna — stąd potrzeba walidacji i audytów (tu wracamy do różnicy między algorytmami a AI: algorytmy wykonują reguły, AI uczy się na danych — więc ważne są dobre dane). Promptowanie (jak i co podajesz modelowi jako kontekst) wpływa na styl, zakres i dokładność odpowiedzi — dobrze sformułowany prompt potrafi zwiększyć precyzję i ograniczyć wymyślanie faktów.
RAO vs klasyczne SEO — porównanie sygnałów rangi
- Semantyka: SEO opiera się w dużej mierze na dopasowaniu słów kluczowych; RAO używa embeddings, więc liczy się znaczenie, nie tylko wystąpienie frazy.
- Aktualność: Tradycyjne SEO premiuje trwałe zasoby (linki, autorytet). RAO dodatkowo faworyzuje świeże, aktualne źródła, bo modele generujące potrzebują najnowszych danych.
- Spójność odpowiedzi: RAO ocenia, czy odpowiedź jest kompletną, jednoznaczną i przydatną informacją — nie tylko czy strona ma dużo treści.
- Źródło danych i autorstwo: W SEO ważny jest autorytet domeny; w RAO liczy się również wiarygodność źródeł użytych do wygenerowania odpowiedzi oraz możliwość odwołania się do nich (traceability).
Przykłady zapytań, w których RAO wygrywa
- Zapytania konwersacyjne: „Jak zoptymalizować onboarding klienta w SaaS przy ograniczonym zespole?” — RAO agreguje najlepsze praktyki z różnych artykułów i tworzy konkretny plan.
- Decyzje biznesowe: „Porównaj koszty i ROI kampanii e‑mailowej vs social media dla małej e‑commerce” — RAO zbiera aktualne case studies i liczy proponowane metryki.
- Agregacja bieżących danych: „Jakie są ostatnie zmiany w przepisach podatkowych dla freelancerów w 2025?” — RAO potrafi połączyć świeże źródła i wskazać daty zmian.
Metryki rzetelności — co mierzyć w RAO
- Faktyczność odpowiedzi: procent wygenerowanych stwierdzeń, które można zweryfikować w źródłach.
- Traceability (śledzenie źródeł): czy system podaje powiązane źródła i fragmenty, z których skorzystał.
- Time‑to‑answer: szybkość wygenerowania wiarygodnej odpowiedzi — kluczowa w obsłudze klienta i dashboardach biznesowych.
- Precision/Recall retrievera: jak dobrze retriever odnajduje relewantne fragmenty bez nadmiaru „szumu”.
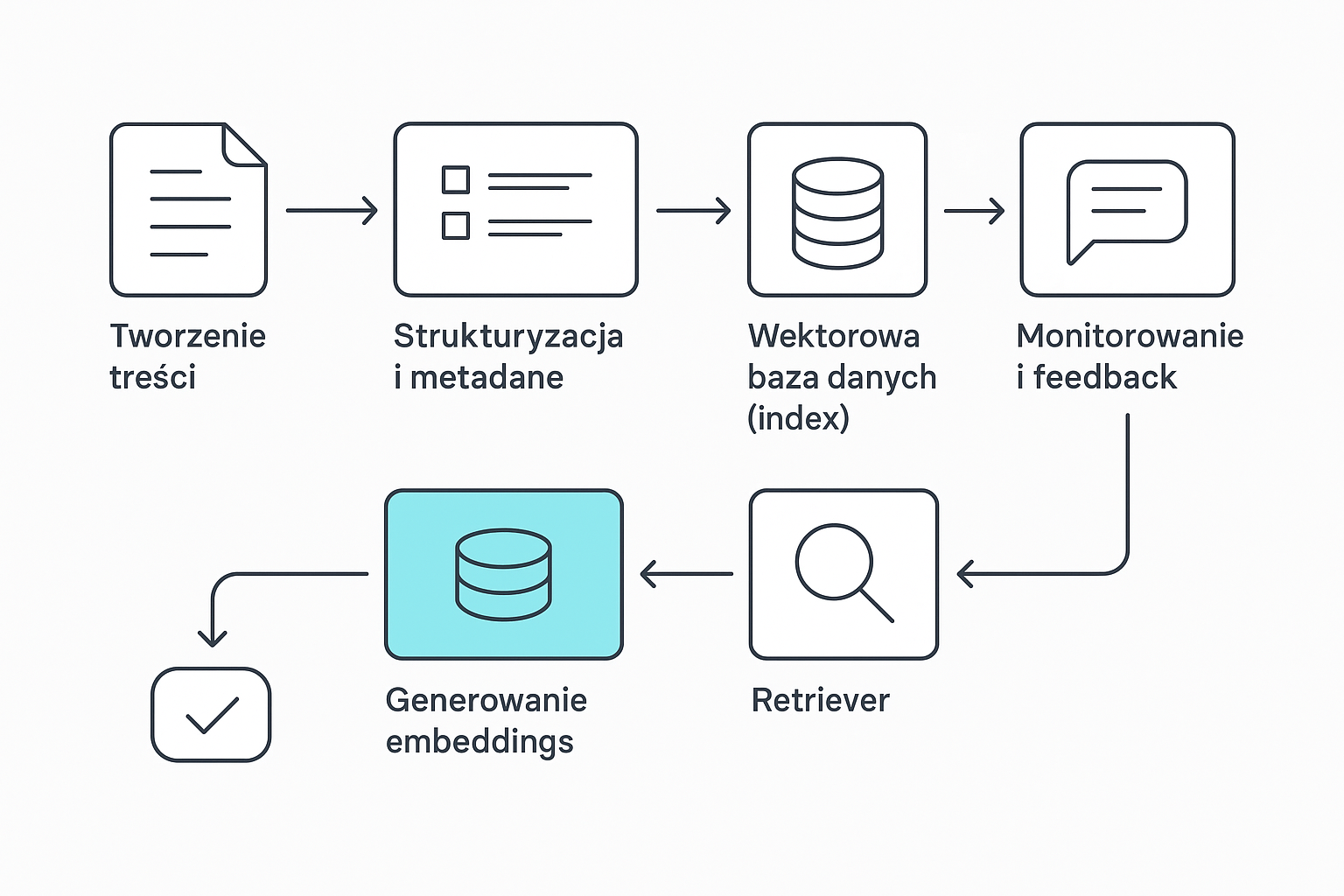
Krótka praktyczna ilustracja — przykładowy workflow RAO
- Publikacja treści (artykuł, dokumentacja, raport).
- Indeksowanie w wektorowej bazie danych — tworzenie embeddings i aktualizacja indeksu.
- Retriever wyszukuje najbardziej relewantne fragmenty względem zapytania użytkownika.
- Reranker porządkuje wyniki, wybierając najlepsze fragmenty.
- Generative reader łączy fragmenty i tworzy spójną odpowiedź, dołączając odwołania do źródeł.
RAO to nie tylko technologia — to inny sposób myślenia o widoczności online. W praktyce oznacza lepsze dopasowanie treści do intencji użytkownika i możliwość szybkiego agregowania aktualnych informacji. Jeśli chcesz zgłębić techniczne i biznesowe implikacje, polecamy dalsza lektura: dlaczego AI popełnia błędy oraz teksty o AI w mediach społecznościowych tu i tu.
W Lumi Zone pomagamy zaprojektować i zautomatyzować ten workflow — od budowy indeksu, przez harmonogramy aktualizacji, po optymalizację promptów i metryk rzetelności. Po tym wyjaśnieniu w następnej sekcji pokażemy praktyczne kroki wdrożenia RAO z automatyzacją: jak zbudować pipeline, jakie narzędzia low‑code/no‑code warto wykorzystać i jak monitorować jakość odpowiedzi.
Praktyczny przewodnik: jak przejść od SEO do RAO — konkretne kroki i checklisty techniczne
Przejście z tradycyjnego SEO do RAO (Response‑Aware Optimization) to nie tylko zmiana strategii treści, to transformacja procesu: zbierania źródeł, formatowania, wersjonowania i automatycznego udostępniania wiedzy dla modeli odpowiadających użytkownikom. Poniżej znajdziesz klarowny plan działania, checklisty techniczne i przykładowe workflowy, które Lumi Zone wdraża u klientów przy użyciu low‑code/no‑code (m.in. n8n).
1. Priorytety treściowe — co musisz zebrać i uporządkować
- FAQ i krótkie odpowiedzi: najczęściej zadawane pytania, przygotowane w formie krótkich, konkretnych odpowiedzi (20–150 słów).
- Aktualne źródła: dokumentacja produktowa, changelogi, polityki, oficjalne artykuły — z datami i wersjami.
- Dokumentacja techniczna: instrukcje krok po kroku, przykłady kodu, endpointy API.
- Metadane kontekstowe: autor, data publikacji, wersja produktu, tagi tematyczne.
2. Elementy techniczne do wdrożenia — checklist
- Strukturyzacja danych: przechowuj treści w ujednoliconym formacie (JSON/Markdown z front‑matters zawierającymi metadane).
- Schema i ujednolicone metadane: zdefiniuj pola takie jak source_id, version, last_updated, intent, confidence_threshold.
- Feedy aktualizacji: webhooki lub RSS/JSON feedy do wykrywania zmian w źródłach.
- Generowanie i automatyczne odświeżanie embeddings: konfiguruj pipeline, który przy publikacji/aktualizacji generuje nowe wektory.
- Wybór vector DB: preferuj hostowane rozwiązania (Pinecone, Weaviate Cloud, Milvus Cloud) dla SLA i skalowalności.
- Wersjonowanie źródeł: tagowanie wersji i retraining/retokenizacja embeddings przy większych zmianach.
- Bezpieczeństwo i dostęp: kontrola dostępu do vector DB i logów zapytań, szyfrowanie danych w tranzycie i spoczynku.
3. Przykładowy stack narzędzi i automatyzowalne workflowy
- Orkiestracja: n8n jako główny orchestrator pipeline’u (low‑code), do łączenia CMS, repozytoriów, embeddingów i vector DB.
- Narzędzia do embeddingów: OpenAI embeddings, Cohere, Hugging Face Inference API — w zależności od kosztu i jakości dla Twojego języka.
- Hostowane vector DB: Pinecone / Weaviate Cloud / Milvus Cloud — szybkie wyszukiwanie semantyczne i skalowalność.
- Monitoring jakości odpowiedzi: zestaw metryk (semantic similarity, human feedback rate, hit/miss ratio) + alerty Slack/Email.
Przykładowe, w pełni automatyzowalne workflowy (n8n):
- Publikacja artykułu w CMS → webhook do n8n → ekstrakcja treści i metadanych → wygenerowanie embeddings → push do vector DB → test query (syntetyczne zapytania) → status OK/alert.
- Zmieniony FAQ w repo → n8n pobiera diff → przebudowa embeddings tylko dla zmienionych rekordów → update w vector DB → notyfikacja moderacji do zatwierdzenia.
- Dzienny skan źródeł (dokumentacja, changelog) → detekcja zmian → batch embeddings + wersjonowanie → automatyczne fallbacky do ostatniej stabilnej wersji przy błędzie.
4. Monitoring, testy i jakość odpowiedzi
- Testy automatyczne: zestaw zapytań kontrolnych po każdej aktualizacji — sprawdź top‑k retrieved, similarity score, oraz zgodność z wersją źródła.
- Human‑in‑loop: losowe sprawdzanie odpowiedzi przez redakcję; feedback wraca do pipeline’u jako trening lub korekta.
- Mierniki biznesowe: czas odpowiedzi klienta, SLA odpowiedzi, procent udanych autosugestii — monitorowane w dashboardzie.
5. Przykłady biznesowe i efekty — czego możesz oczekiwać
- Redukcja manualnej pracy redakcyjnej: automatyzacja generowania embeddings i push do DB może zmniejszyć ręczną aktualizację o 60–80%.
- Szybsze aktualizacje treści: czas od publikacji do dostępności w systemie odpowiedzi spada z dni do minut (typowo <30 min przy dobrze skonfigurowanym pipeline).
- Lepsza konwersja: trafniejsze, krótkie odpowiedzi i aktualne info podnoszą satysfakcję użytkownika — często wzrost konwersji o 10–25% w kanałach obsługi klienta.
Lumi Zone specjalizuje się we wdrożeniach low‑code/no‑code (n8n), automatyzacji publikacji i monitoringu. Zbudujemy dla Ciebie pipeline, który odciąży zespół, zapewni wersjonowanie źródeł i ciągłe odświeżanie wiedzy w modelach.
Mini‑case
Firma X (SaaS): zautomatyzowaliśmy feed FAQ + pipeline embeddings (n8n → OpenAI embeddings → Pinecone). Efekt: czas udostępnienia zaktualizowanej odpowiedzi skrócił się z 48 godzin do 25 minut, a ręczna praca redakcyjna zmniejszyła się o 70%. Konwersja w formularzu wsparcia wzrosła o 14% w trzy miesiące.

Podsumowanie i wnioski
RAO to naturalny krok dalej: zamiast skupiać się tylko na widoczności strony (SEO), przechodzimy do optymalizacji dostarczania wiedzy — trafnej, szybkiej i kontekstowej odpowiedzi na potrzeby użytkownika. To zmiana paradygmatu, która pozwala firmom oszczędzać czas, zwiększać konwersje i lepiej wykorzystać wiedzę zgromadzoną w organizacji.
Jednocześnie pamiętaj o ograniczeniach: AI wspiera decyzje, ale nie zastępuje odpowiedzialnego nadzoru. Badania jasno pokazują, że systemy uczące się wymagają regularnych audytów, walidacji danych i kontroli etycznej, aby nie powielać błędów czy uprzedzeń.
Jako Lumi Zone oferujemy praktyczne kroki: bezpłatny audyt RAO/analizę gotowości oraz szybki pilotaż z użyciem n8n i vector DB, by pokazać realne korzyści w 4–8 tygodni. Nasze wdrożenia łączą automatyzację low-code z procesem audytu, tak by technologia działała bezpiecznie i efektywnie.
Chcesz zacząć? Umów bezpłatny audyt RAO — napisz do nas na kontakt@lumizone.pl lub przez formularz na stronie Lumi Zone. Razem zaplanujemy pilotaż i harmonogram audytów etycznych.